
The inference platform segment is carving out a distinct place in the crowded AI infrastructure market. Instead of competing on raw GPU rentals, these companies focus on simplifying the complex software stack required to run and scale models. That emphasis gives them a stronger competitive advantage than pure-play GPUaaS providers, which are increasingly commoditized.
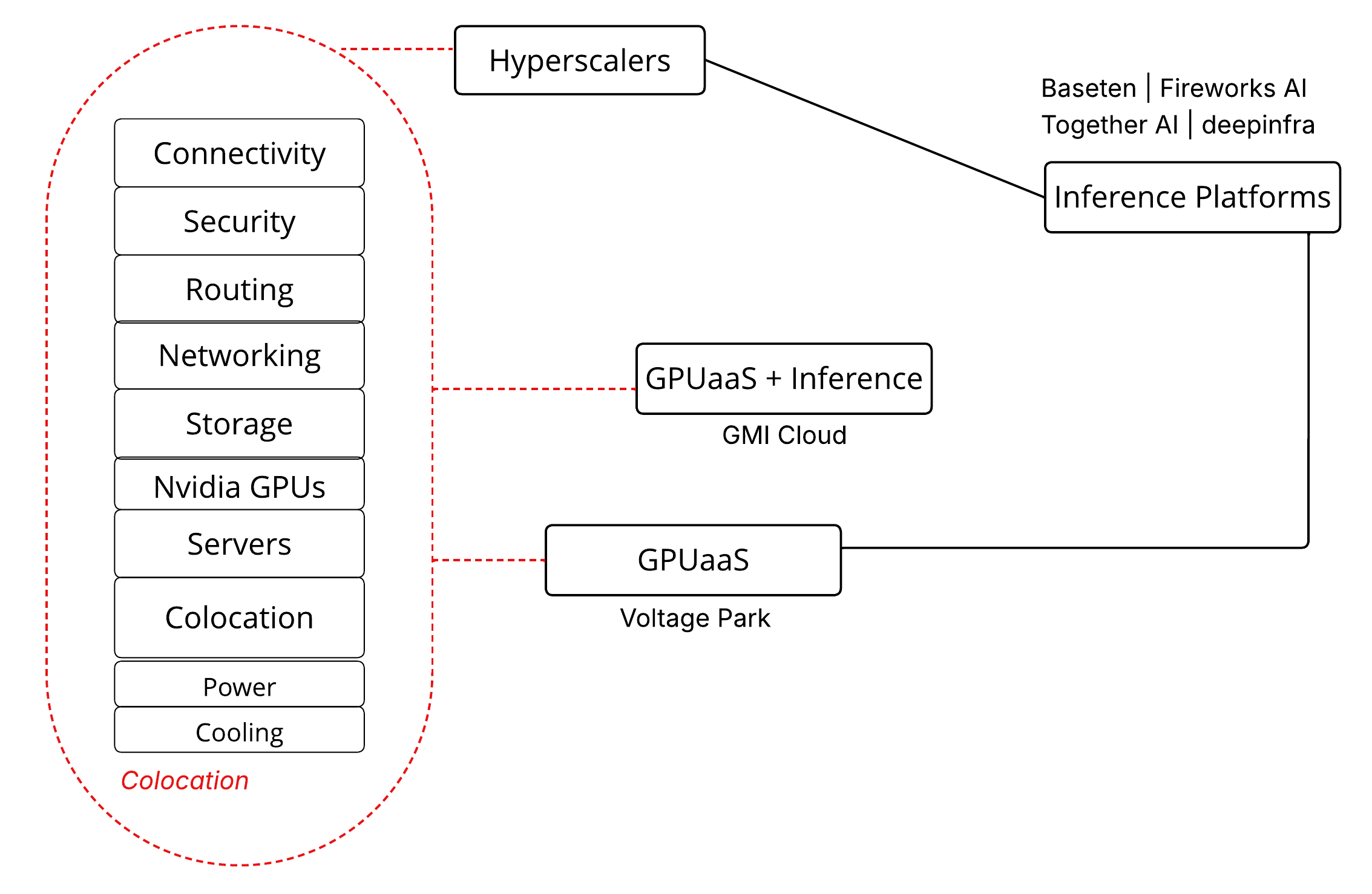
Unlike GPU resellers who pour capital into hardware, networking, and data centers, inference platforms attract venture funding to build differentiated software layers that make deploying and operating models easier, faster, and more cost-efficient.
Leading the way in this category are Baseten, Fireworks AI, and Together AI, with newer entrants like Deepinfra quickly gaining traction.
Key Players at a Glance
| Startup | Founded | # of Employees | Total Raised | Revenue ARR | Valuation |
| Baseten | 2019 | 120 | $285M | N/A | $2.15B |
| Fireworks AI | 2022 | 124 | $77M | $200M-$300M | $4B |
| Together AI | 2022 | 252 | $534M | ~$100M | $3.3B |
| deepinfra | 2022 | 11 | $26M | N/A | N/A |
Deploying and Scaling Models
What separates inference platforms from GPUaaS providers isn’t the hardware; it’s the software layer that makes deploying and scaling models effortless. Renting a GPU gives you raw power, but little else. Running a model in production still means dealing with containers, dependencies, autoscaling, logging, monitoring, and integrations. That complexity is exactly what companies like Baseten, Fireworks AI, and Together AI are solving.
Take Baseten as an example. Developers can choose from a library of prepackaged models like image generation, speech recognition, and large language models, and deploy them in seconds with a single command or API call. Under the hood, Baseten handles containerization, autoscaling, GPU orchestration, and monitoring, removing the operational overhead that comes with managing infrastructure.
Fireworks AI takes a slightly different angle. Their platform is built for low-latency inference and optimized serving of large language models. By focusing on token throughput and response times, they give developers performance guarantees that raw GPU rentals can’t. Fireworks also supports fine-tuning and custom deployments, giving teams flexibility to build differentiated AI applications without touching the gritty infrastructure.
Together AI leans into openness and collaboration. They provide a marketplace of open-source models that can be deployed at scale with optimized performance, along with APIs for customization. Their emphasis is on democratizing access, letting developers harness state-of-the-art models without wrestling with GPU scheduling or distributed training setups.
Collectively, these features like instant deployment, optimized serving for speed and cost, autoscaling, monitoring, and open model access are what separate inference platforms from the GPUaaS crowd. Instead of competing in a race to rent out GPUs at shrinking margins, they built software that makes GPUs accessible and useful for real workloads. This ability to abstract away infrastructure while adding tangible value has given inference platforms a strong competitive advantage.
What Comes Next
The next stage for inference platforms is likely to be about moving up the stack. Today, most focus on serving and scaling models, but tomorrow’s differentiation may come from offering fine-tuning capabilities, orchestration frameworks for agentic AI, and vertical-specific stacks tailored to industries like healthcare, finance, or energy.
Some platforms are already experimenting in this direction, layering on tools for customization, monitoring, and compliance. Others may partner with or acquire companies that specialize in data pipelines, training infrastructure, or agent frameworks to broaden their offerings. In a market where GPU access will only become more commoditized, the platforms that succeed will be those that keep climbing the software stack and embedding themselves deeper into customer workflows.
Conclusion
Inference platforms have carved out a unique niche in the AI infrastructure ecosystem. While GPUaaS providers battle it out in an increasingly commoditized market, companies like Baseten, Fireworks AI, and Together AI differentiate themselves by tackling the harder problem: making model deployment and scaling seamless. By packaging models for instant use, optimizing for low-latency serving, and building APIs that abstract away infrastructure headaches, they’ve turned GPUs into a service that’s not just rentable—but truly usable.